
CPI 的 loop 只會跑一次
#include "mpi.h"
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
double f( double );
double f( double a )
{
return (4.0 / (1.0 + a*a));
}
int main( int argc, char *argv[])
{
int done = 0, n, myid, numprocs, i=0, count=0;
double PI25DT = 3.141592653589793238462643;
double mypi, pi, h, sum, x;
double startwtime = 0.0, endwtime;
int namelen;
char processor_name[MPI_MAX_PROCESSOR_NAME];
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
MPI_Get_processor_name(processor_name,&namelen);
fprintf(stderr,"Process %d on %s\n",
myid, processor_name);
n = 0;
while (!done)
{
count++;
printf("Node %d : loop runs %d times\n", myid, count);
if (myid == 0)
{
/*
printf("Enter the number of intervals: (0 quits) ");
scanf("%d",&n);
*/
if (n==0) n=100; else n=0;
startwtime = MPI_Wtime();
}
printf("Node %d : n = %d before MPI_Bcast\n", myid, n);
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
printf("Node %d : n = %d before MPI_Bcast\n", myid, n);
if (n == 0)
done = 1;
else
{
h = 1.0 / (double) n;
sum = 0.0;
for (i = myid + 1; i <= n; i += numprocs)
{
x = h * ((double)i - 0.5);
sum += f(x);
}
mypi = h * sum;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (myid == 0)
{
printf("pi is approximately %.16f, Error is %.16f\n",
pi, fabs(pi - PI25DT));
endwtime = MPI_Wtime();
printf("wall clock time = %f\n",
endwtime-startwtime);
}
}
}
MPI_Finalize();
return 0;
}
結果
去掉 while loop 也能執行,是因為 while loop 的目的為展現出,每個 Node 在第二次進入 while loop 時,Node 0 會將 n = 0 藉由 MPI_Bcast 廣播出去。由下圖可發現,每個 Node 只會執行二次,因為在 MPI_Bcast 中,每個 Node 皆會被 lock 住,直到 Node 0 將 n = 0 送到其它的 Node ,每個 Node 才會接著往下做,不過 lock 的機制,似乎與「群」有關,有些 function 如 sprintf,本身就是一個群,所以可以看見前面所有的 Node 會全部將結果顯示在螢幕上才繼續做下一「群」的程式,而我們也可以發現,在下一「群」的程式中,也是將這「群」的程式執行完後才將結果顯示出。

MPICH Performance Report
Machine Specification
| Node | 8 nodes (1 server , 7 client provide disks) |
| CPU | Intel(R) Core(TM)2 Quad CPU Q6600 @ 2.40GHz |
| Memory | 2GB DDR2 667 (each node) |
CPI.c
Description
這是一個 mpich 內附用來算 pi 的程式。
Performance
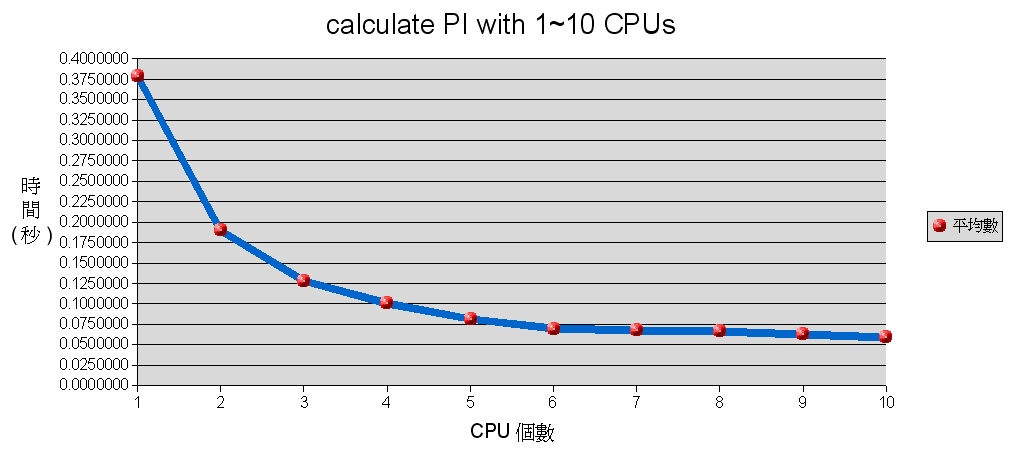
以下為使用 1~10 顆的 CPU 測試 100 次的結果
| PI | 3.14159265358979323846 |
| Our result | 3.14159265358979267191 |
| error | 0.00000000000000056655 |
cpus 平均數 1 0.3792575 2 0.1898436 3 0.1280467 4 0.1004294 5 0.0812890 6 0.0696091 7 0.0672654 8 0.0662498 9 0.0625782 10 0.0587502

Last modified 18 years ago
Last modified on Apr 15, 2008, 5:13:32 PM
Attachments (3)
- cpi-analysis10.ods (15.9 KB) - added by wade 18 years ago.
- cpi_01.png (19.6 KB) - added by wade 18 years ago.
- cpi_02.png (166.1 KB) - added by wade 18 years ago.
{kind=link}
{kind=link}
Download all attachments as: .zip